- Surveys & Programs
- Data & Tools
- Fast Facts
- News & Events
- Publications & Products
- About Us
Table of Contents | Search Technical Documentation | References
NAEP Technical DocumentationProcedures for Estimating Group Scale Score Statistics and Their Standard Errors
|
Using Plausible Values to Estimate Group Scale Score Statistics and Their Standard Errors Potential Bias in Analysis Results Using Variables Not Included in the Model |
|||
Statistics (t) of interest (e.g., the average proficiency in a group, the percentage students in a group performing at or above a cutpoint as in the current text), t(θ,Y), are estimated depending on the latent proficiency variable (θ) and student group indicators Y. Because proficiency is not directly observed, but inferred from responses to test questions, X, and a set of Item Response Theory models, t is approximated as follows:
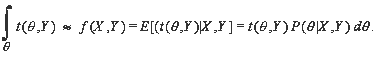
In words, the statistic is estimated by taking the expectation of the statistic over the posterior distribution of θ, given observed answers to cognitive (X) and background (Y) items. There are several approaches to performing this computation. NAEP uses an imputation approach where the integral is approximated by random draws from the posterior distribution P(θ|X,Y), and by aggregating these draws according to group membership indicators Y. These draws are called plausible values. Please note that the description here refers to a univariate case and that a multivariate extension involves a multivariate integration using a matrix Θ instead of a vector.
Based on the plausible values, scale score statistics and their standard errors can be estimated.
Last updated 16 September 2009 (GF)