- Surveys & Programs
- Data & Tools
- Fast Facts
- News & Events
- Publications & Products
- About Us
NAEP Technical DocumentationDatabase Quality Control: Prior to 2013
|
| ||
Summary of Quality Control Error Analysis for the Data Entry
|
The manual process described below proved to be a successful quality control process. However, it was somewhat tedious, time-consuming, and costly.
Beginning in 2013, this process was replaced by a more automated comparison process that compares the statistical properties of the response data as processed and the same data as they reside on the NAEP Materials Processing and Scoring contractor's system. This new approach represents a more comprehensive examination of the response data. In addition, the statistical comparison can be repeated throughout the analysis period to ensure stability of the database. Tables are produced by grade and subject that provide a summary of the comparisons.
Quality Control Analyses 2000–2012
Through the years, the NAEP database has been found to be more than accurate enough to support the analyses that can be done. Overall, no statistically significant difference in observed error rates was detected from year to year.
The purpose of a quality control analysis is to assess the quality of the data resulting from the complete data-entry system, beginning with the actual instruments collected in the field and ending with the final machine-readable database used in the analyses. The process involved the selection of instruments at random from among those returned from the field and the comparison of each entire instrument, character by character, with its representation in the final database. In this way, it was possible to measure the error rates in the data as well as the success of the data-entry system.
The observed error rate cannot be taken at face value. For example, let us say a sample of school questionnaires that were selected for close inspection contained two errors out of a total of 2,251 characters. To conclude that the entire school questionnaire database has an error rate of ![]() or .0009, would be too optimistic; we may simply have been lucky (or unlucky) with this particular random sample. What is needed is an indication of how bad the true error rate might be, given what we observed. Such an indication is provided by confidence limits. Confidence limits are the numbers at the upper and lower end of a confidence interval. Taking the 95 percent confidence interval as an example, it indicates that if we used the same sampling method to select different samples and computed an interval estimate for each sample, we would expect the true error rate to fall within the interval estimates 95 percent of the time. In this analysis, the specified range is an error rate between zero and some maximum value beyond which we are confident at a specified level (traditionally 99.8 percent) that the true error rate does not lie. The specified context or distribution turns out to be the cumulative binomial probability distribution. The following example will demonstrate this technique.
or .0009, would be too optimistic; we may simply have been lucky (or unlucky) with this particular random sample. What is needed is an indication of how bad the true error rate might be, given what we observed. Such an indication is provided by confidence limits. Confidence limits are the numbers at the upper and lower end of a confidence interval. Taking the 95 percent confidence interval as an example, it indicates that if we used the same sampling method to select different samples and computed an interval estimate for each sample, we would expect the true error rate to fall within the interval estimates 95 percent of the time. In this analysis, the specified range is an error rate between zero and some maximum value beyond which we are confident at a specified level (traditionally 99.8 percent) that the true error rate does not lie. The specified context or distribution turns out to be the cumulative binomial probability distribution. The following example will demonstrate this technique.
Let us say that 1,000 booklets were processed, each with 100 characters of data transcribed for a total of 100,000 characters. Further, let j represent the number of character errors (five in this example), in a random sample of booklets that were completely checked (50 in this example). In other words, five errors were found in a sample of 5,000 characters. The following expression may be used to establish the probability that the true error rate is .0025 or less, rather than a single-value estimate of the observed rate, one in a thousand (.001):
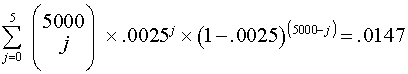
This is the sum of the probability of finding zero errors plus the probability of finding one error plus (and so on, working the equation through to the greatest value, in this case five) plus the probability of finding five errors in a sample of 5,000 with a true error rate of .0025; that is, the probability of finding five or fewer errors by chance when the true error rate is .0025. Notice that we did not use the size of the database in this expression. Actually, the assumption here is that our sample of 5,000 was drawn from a database that is infinite. The closer the size of the sample verified relative to the size of the actual database, the more confidence we can have in the observed error rate; for example, had there been only 5,000 in the total database, our sample would have included all the data, and the observed error rate would have been the true error rate. The result of the above computation allows us to say, conservatively, that .0025 is an upper limit on the true error rate with 98.53 percent (i.e., 1 - .0147) confidence; that is, we can be quite sure that our true error rate is no larger than .0025. For NAEP quality control we use a more stringent confidence limit of 99.8 percent, which yields an even more conservative upper bound on the true error rate; with 99.8 percent confidence, we would state that the true error rate in this example is no larger than .0031, rather than .0025.
Calculations of true probabilities based on a combinatorial analysis have been done (e.g.,
Grant 1964). Even when the sample was as much as 10 percent of a population of 50, the estimate of the probability based on the binomial theorem was not much different from the correct probability. NAEP does not sample at a rate greater than about 2 percent. Thus, the computations of the upper limits on the true error rates based on the binomial theorem are likely to be highly accurate approximations.
Last updated 02 November 2022 (SK)