- Surveys & Programs
- Data & Tools
- Fast Facts
- News & Events
- Publications & Products
- About Us
Table of Contents | Search Technical Documentation | References
NAEP Technical DocumentationReplicate Variance Estimation for the 2017 Assessment
Variances for NAEP assessment estimates are computed using the paired jackknife replicate variance procedure. This technique is applicable for common statistics, such as means and ratios, and differences between these for different subgroups, as well as for more complex statistics such as linear or logistic regression coefficients.
In general, the paired jackknife replicate variance procedure involves initially pairing clusters of first-stage sampling units to form H variance strata (h = 1, 2, 3, ..., H) with two units per stratum. The first replicate is formed by assigning, to one unit at random from the first variance stratum, a replicate weighting factor of less than 1.0, while assigning the remaining unit a complementary replicate factor greater than 1.0, and assigning all other units from the other (H - 1) strata a replicate factor of 1.0. This procedure is carried out for each variance stratum resulting in H replicates, each of which provides an estimate of the population total.
In general, this process is repeated for subsequent levels of sampling. In practice, this is not practicable for a design with three or more stages of sampling, and the marginal improvement in precision of the variance estimates would be negligible in all such cases in the NAEP setting. Thus in NAEP, when a two-stage design is used – sampling schools and then students – beginning in 2011 replication is carried out at both stages. (See Rizzo and Rust (2011) for a description of the methodology.) When a three-stage design is used, involving the selection of geographic Primary Sampling Units (PSUs), then schools, and then students, the replication procedure is only carried out at the first stage of sampling (the PSU stage for noncertainty PSUs, and the school stage within certainty PSUs). In this situation, the school and student variance components are correctly estimated, and the overstatement of the between-PSU variance component is relatively very small.
The jackknife estimate of the variance for any given statistic is given by the following formula:
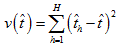
-
 represents the full sample estimate of the given statistic, and
represents the full sample estimate of the given statistic, and  represents the corresponding estimate for replicate
h.
represents the corresponding estimate for replicate
h.
Each replicate undergoes the same weighting procedure as the full sample so that the jackknife variance estimator reflects the contributions to or reductions in variance resulting from the various weighting adjustments.
The NAEP jackknife variance estimator is based on 62 variance strata resulting in a set of 62 replicate weights assigned to each school and student.
The basic idea of the paired jackknife variance estimator is to create the replicate weights so that use of the jackknife procedure results in an unbiased variance estimator for totals and means, which is also reasonably efficient (i.e., has a low variance as a variance estimator). The jackknife variance estimator will then produce a consistent (but not fully unbiased) estimate of variance for (sufficiently smooth) nonlinear functions of total and mean estimates such as ratios, regression coefficients, and so forth (Shao and Tu, 1995).
The development below shows why the NAEP jackknife variance estimator returns an unbiased variance estimator for totals and means, which is the cornerstone to the asymptotic results for nonlinear estimators. See for example Rust (1985). This paper also discusses why this variance estimator is generally efficient (i.e., more reliable than alternative approaches requiring similar computational resources).
The development is done for an estimate of a mean based on a simplified sample design that closely approximates the sample design for first-stage units used in the NAEP studies. The sample design is a stratified random sample with
H strata with population weights
Wh, stratum sample sizes
nh, and stratum sample means ![]() . The population estimator
. The population estimator ![]() and standard unbiased variance estimator
and standard unbiased variance estimator ![]() are:
are:
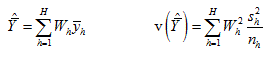
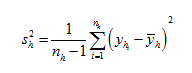
The paired jackknife replicate variance estimator assigns one replicate
h=1,…,
H to each stratum, so that the number of replicates equals
H. In NAEP, the replicates correspond generally to pairs and triplets (with the latter only being used if there are an odd number of sample units within a particular primary stratum generating replicate strata). For pairs, the process of generating replicates can be viewed as taking a simple random sample (J) of size
nh/2 within the replicate stratum, and assigning an increased weight to the sampled elements, and a decreased weight to the unsampled elements. In certain applications, the increased weight is double the full sample weight, while the decreased weight is in fact equal to zero. In this simplified case, this assignment reduces to replacing
![]() with
with ![]() , the latter being the sample mean of the sampled
nh/2 units. Then the replicate estimator corresponding to stratum
r is
, the latter being the sample mean of the sampled
nh/2 units. Then the replicate estimator corresponding to stratum
r is
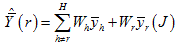
The
r-th term in the sum of squares for  is thus:
is thus:
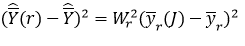
In stratified random sampling, when a sample of size nr/2 is drawn without replacement from a population of size nr,, the sampling variance is
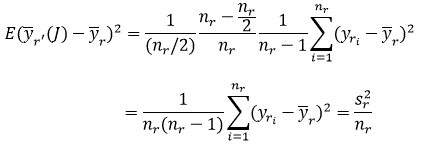
See for example Cochran (1977), Theorem 5.3, using nr, as the “population size,” nr/2 as the “sample size,” and sr2 as the “population variance” in the given formula. Thus,
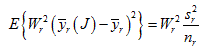
Taking the expectation over all of these stratified samples of size nr/2, it is found that
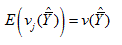
In this sense, the jackknife variance estimator “gives back” the sample variance estimator for means and totals as desired under the theory.
In cases where, rather than doubling the weight of one half of one variance stratum and assigning a zero weight to the other, the weight of one unit is multiplied by a replicate factor of (1+δ), while the other is multiplied by (1- δ), the result is that
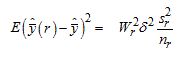
In this way, by setting δ equal to the square root of the finite population correction factor, the jackknife variance estimator is able to incorporate a finite population correction factor into the variance estimator.
In practice, variance strata are also grouped to make sure that the number of replicates is not too large (the total number of variance strata is usually 62 for NAEP). The randomization from the original sample distribution guarantees that the sum of squares contributed by each replicate will be close to the target expected value.
For triples, the replicate factors are perturbed to something other than 1.0 for two different replicate factors, rather than just one as in the case of pairs. Again in the simple case where replicate factors that are less than 1 are all set to 0, with the replicate weight factors calculated as follows.
For unit i in variance stratum r
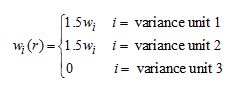
where weight wi is the full sample base weight.
Furthermore, for r' = r + 31 (mod 62):

And for all other values r*, other than r and r´,wi(r*) = 1.
In the case of stratified random sampling, this formula reduces to replacing  with
with ![]() for replicate
r, where
for replicate
r, where ![]() is the sample mean from a “2/3” sample of 2nr/3 units from the
nr sample units in the replicate stratum, and replacing
with
is the sample mean from a “2/3” sample of 2nr/3 units from the
nr sample units in the replicate stratum, and replacing
with ![]() for replicate
r', where
for replicate
r', where ![]() is the sample mean from another overlapping “2/3” sample of 2nr/3 units from the
nr sample units in the replicate stratum.
is the sample mean from another overlapping “2/3” sample of 2nr/3 units from the
nr sample units in the replicate stratum.
The r-th and r´-th replicates can be written as:
![[First equation] cap y hat bar open paren r close paren equals summation from h does not equal r to cap h open paren cap w subscript h times y bar subscript h close paren plus cap w subscript r times y bar subscript r open paren cap j close paren.[Second equation] cap y hat bar open paren r prime close paren equals summation from h does not equal r to cap h open paren cap w subscript h times y bar subscript h close paren plus cap w subscript r times y bar subscript r prime open paren cap j close paren](/nationsreportcard/subject/tdw/subject/weighting/images/replicate_variance_estimation12_and_13.gif)
From these formulas, expressions for the r-th and r´-th components of the jackknife variance estimator are obtained (ignoring other sums of squares from other grouped components attached to those replicates):
![[First equation] open paren cap y hat bar open paren r close paren minus cap y hat bar close paren squared equals open paren cap w subscript r close paren squared times open paren y bar subscript r open paren cap j close paren minus y bar subscript r close paren squared.[Second equation] open paren cap y hat bar open paren r prime close paren minus cap y hat bar close paren squared equals open paren cap w subscript r close paren squared times open paren y bar subscript r prime open paren cap j close paren minus y bar subscript r close paren squared](/nationsreportcard/subject/tdw/subject/weighting/images/replicate_variance_estimation14_and_15.gif)
These sums of squares have expectations as follows, using the general formula for sampling variances:
![[First equation] cap e open paren y bar subscript r open paren cap j close paren minus y bar subscript r close paren squared equals open bracket one divided by open paren two times n subscript r divided by three close paren close bracket times open bracket open subbracket n subscript r minus open paren two times n subscript r divided by three close paren close subbracket divided by n subscript r close bracket times open bracket one divided by open paren n subscript r minus one close paren close bracket times summation from i equals one to n subscript r open paren y subscript r subsubscript i minus y bar subscript r close paren squared equals open bracket one divided by open subbracket two times n subscript r times open paren n subscript r minus one close paren close subbracket close bracket times summation from i equals one to n subscript r open paren y subscript r subsubscript i minus y bar subscript r close paren squared equals s subscript r squared divided by two times n subscript r. [Second equation] cap e open paren y bar subscript r prime open paren cap j close paren minus y bar subscript r close paren squared equals open bracket one divided by open paren two times n subscript r divided by three close paren close bracket times open bracket open subbracket n subscript r minus open paren two times n subscript r divided by three close paren close subbracket divided by n subscript r close bracket times open bracket one divided by open paren n subscript r minus one close paren close bracket times summation from i equals one to n subscript r open paren y subscript r subsubscript i minus y bar subscript r close paren squared equals open bracket one divided by open subbracket two times n subscript r times open paren n subscript r minus one close paren close subbracket close bracket times summation from i equals one to n subscript r open paren y subscript r subsubscript i minus y bar subscript r close paren squared equals s subscript r squared divided by two times n subscript r](/nationsreportcard/subject/tdw/subject/weighting/images/replicate_variance_estimation16_and_17.gif)
Thus,
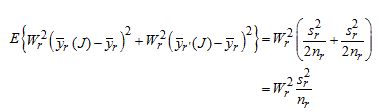
as desired again.
Last updated 29 July 2022 (PG)